The server as we know it is dying [mic drop]. Enter serverless!
This blog post first appeared on the New Relic blog on March 6th, 2018.

By Kevin Downs, Solutions Strategy Director
To many, this may not come as a complete surprise. But if for some reason you haven’t been paying attention, the long, slow death of the server began in 2014, when Amazon Web Services(AWS) introduced AWS Lambda. For reference, here is a description of Lambda from AWS:
“With Lambda, you can run code for virtually any type of application or backend service—all with zero administration. Just upload your code and Lambda takes care of everything required to run and scale your code with high availability. You can set up your code to automatically trigger from other AWS services or call it directly from any web or mobile app.”
What “serverless” really means
AWS Lambda is sometimes incorrectly referred to by the generic name “serverless.” However, serverless is a more general term that includes all cloud services that don’t require you, the administrator, to spin up a server to run it. Lambda is just one such cloud service. Another example of a serverless service is notification. AWS has a service called Amazon Simple Notification Service (SNS). You don’t spin up a server and install SNS on it—you consume SNS.
There are many other examples of serverless services, so when I refer to serverless, I’m talking about any and all cloud services that don’t require (or allow) you to administer a server.
Still, although various serverless services have been around for a while now, it was AWS Lambda that dealt the first real death blow for servers as we’ve known and used them. Since then, both Microsoft Azure and Google Cloud Platform have come out with their own answers to Lambda called Functions. I’ll use the generic term “functions” to refer to this type of serverless service.
A new role for ops in a serverless world
Lambda’s debut in 2014 prompted me to ponder where operations (the ops part of DevOps) should focus its priorities in a world where developers (the dev part of DevOps) have the ability to spin up, scale up, scale out, consume, repurpose, scale down, scale in, shut down, and retire infrastructure on their own. The fact that developers can now do all of this without looking over the wall for operations support represents a huge shift in workflow. I have total respect for developers, but after two decades on the technical support and monitoring side of the business, sometimes I feel like they’ve made off with the keys to the cloud candy store—and that’s a good thing!
So where is all this brave new serverless stuff going to take operations? Should operations staff start polishing their resumes or think about switching careers? Basically, should operations be worried their role is in jeopardy?
The answer is no, not by a long shot. Developers are not going to take over operations’ job responsibilities. Robots are not going to invade our domain and mock our pocket protectors. In other words …

Six priorities ops should focus on
Of course, that doesn’t mean that nothing is going to change. The rise of serverless and functions and the empowerment of developers will indeed affect how ops teams work. Given that, I have six suggestions (in alphabetical order) for where ops folks should focus their priorities in a DevOps serverless world:
1. Automation
As developers increasingly employ powerful scripted architecture services, operations will need to make sure they are one step (if not many steps) ahead. That means everything from checking to see if all the components are running correctly to making sure developers are cleaning up after themselves (“Are you done with that container?”). Operations folks must get good at automating their daily tasks, fast! Remember, developers are using that same automation to create infrastructure and functions as fast as they can, too.
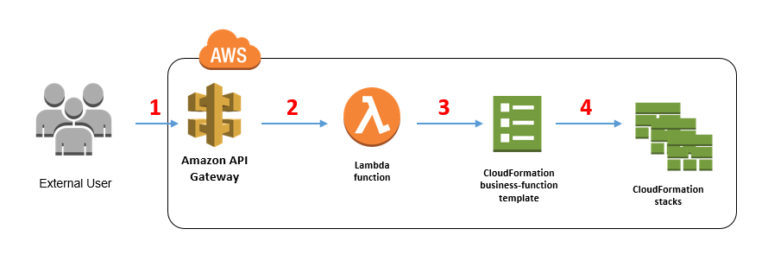
My recommendation: Study up on DevOps deployment orchestration tools such as AWS CloudFormation and similar services from other cloud vendors.
2. Cost optimization
This issue has been ramping up for a while. Once upon a time, IT budgets were authorized, projects were approved, and infrastructure was purchased. Both developers and operations didn’t really care about costs because that was all handled at the project-approval level. After that, developers were the consumers of infrastructure and operations was there to support that infrastructure, keeping the lights on.
Now, operations has a large role to play in understanding where and how to balance cloud-computing’s three-legged stool: availability, performance, and cost. Ops is uniquely positioned to answer such questions as, Are oversized instances being used? Is the autoscaler properly configured to scale down? Are storage and database resources properly being consumed? This becomes essential as developers gain a seemingly unfettered ability to create infrastructure and code functions. In this new environment, operations is the first line of defense against unexpected cloud bills.
My recommendation: Become familiar with how cloud vendors charge for their services and shine a light into that dark, scary place (see “Monitoring” below).
3. Disaster recovery
We all know things fail, even cloud services. Operations will always need to think about worst-case scenarios and make sure the environments being created are properly configured for failover. We have come a long way from offsite tape-backup repositories, but the same theories apply: what happens if this part of the architecture fails? Operations needs to make sure that as developers script infrastructure and code functions, failover strategies are in place.
My recommendation: Break things on purpose (in development environments, of course) to learn how to create fault-tolerant, multi-region architectures … then try to break those.
4. Monitoring
This one can’t be overemphasized: monitor everything you can! If you don’t monitor it, you can’t know if it’s working (or was working) correctly or at all. In a cloud world, monitoring becomes more important as services that were running one minute can be decommissioned in the blink of an eye. Operations needs to monitor serverless services to make sure they are performing (or did perform) as expected. Monitoring cloud services gives operations essential information to improve future cloud service usage.
My recommendation: Incorporate the cloud vendor’s built-in monitoring where appropriate. However, do you fully trust the fox to guard the hen house? Look to third-party monitoring solutions to gain an unbiased view. Critically, a third-party monitoring solution is essential to fully instrument and understand complex multi-cloud as well as hybrid (cloud and on-premise) architectures. Only then will you be able to understand the complete picture, an end-to-end monitoring view that shows your applications and their relationships to the cloud services they rely upon.
5. Security
Cloud-based security can actually be more secure than the on-premise variety. Yet, “with great power comes great responsibility.” Operations still needs to manage, control, and maintain proper access rights to applications and systems to minimize vulnerability to breaches and avoid improperly exposing private data. With the rise of scripted infrastructure and functions, ops must offer the required cloud services to devs while making sure that those services are secured properly.
My recommendation: Establish best-practice security processes as recommended by your cloud vendors and incorporate a cloud security expert into your cloud journey (either an internal stakeholder or an external resource).
6. Troubleshooting
Always an essential skill for operations, troubleshooting is pretty much what ops does. That’s not likely to change—operations will always need to figure out what went wrong. With cloud services, though, troubleshooting can become even more complex as operations stretch to take into account things like decoupled applications, scripted infrastructure, and functions.
Recommendation: Keep doing what you’re doing. You wouldn’t be in operations if you didn’t have an inner Sherlock Holmes lurking around in there somewhere.
No rest for the weary ops team
You may think, “We just got here and moved to the cloud. We moved our physical servers to instances. We moved our databases as well. Even though we lost a little visibility into the underpinning infrastructure, we gained some cool new features and abilities (I’m looking at you AWS CloudFormation). Now, they go ahead and pull the rug out from under us with this whole functions serverless thing. Can’t we pause for a little bit?”
No, that’s not going to happen. The world is moving rapidly toward serverless as the default option. Of course, not everything currently lends itself well to serverless and/or functions, so it may take a few years for the avalanche to show itself, but, ready or not, it’s coming!
Fortunately, operations teams are uniquely suited to support our organizations during this next phase of the cloud journey. We may need to learn a few new tools and tricks, but that’s always been part of the operations job description, right?
Your turn
You’ve read my thoughts. Where should operations focus its priorities in a DevOps world where “serverless” is becoming the norm rather than the exception? Let us know on X (Twitter) @NewRelic using hashtag #ServerlessOps.