Today New Relic is making the new infrastructure monitoring experience generally available to help DevOps, SRE, and IT Operations teams proactively identify and resolve issues in their public, private, and hybrid cloud infrastructure.
This blog post first appeared on the New Relic blog, on February 16th, 2022.

By Kevin Downs, Solutions Strategy Director
Unified visibility for all infrastructure monitoring components
This new monitoring experience delivers usability and efficiency, with end-to-end platform context engineers can use to troubleshoot when issues arise.
New Relic Infrastructure monitoring addresses some common problems operations engineers have with detecting, triaging, and troubleshooting any health issues. First, the sheer number of entities is increasing at an exponential rate with the rapid adoption of hybrid cloud, workload containerization, and the move to microservices-based architectures. Second, a large percentage of infrastructure is now ephemeral, which is unmanageable without sufficient change detection. Last, infrastructure isn’t just ITOps’ responsibility; it is now code that all engineers should be able to navigate to isolate performance bottlenecks. Our new experience helps you overcome these obstacles in several ways. If you’re a current New Relic user, jump right into the new infrastructure monitoring UI.
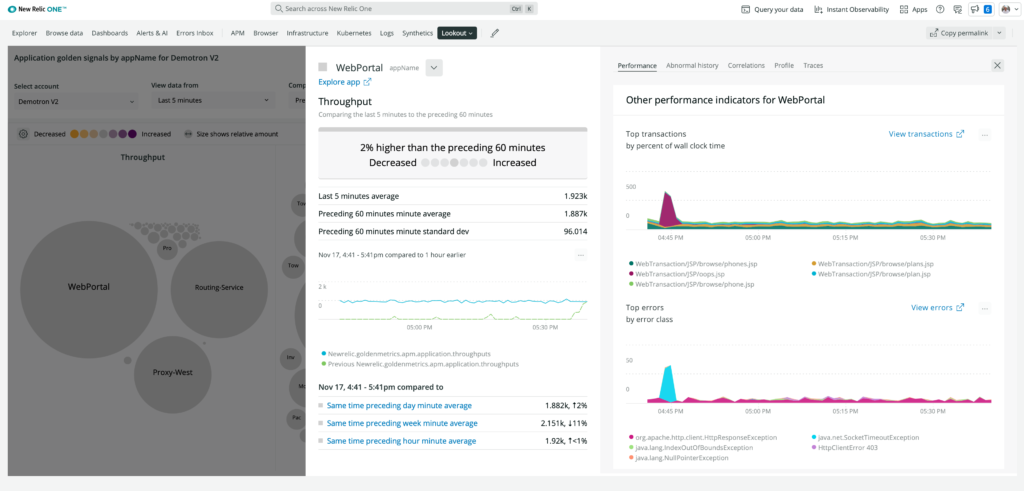
Detect issues before customers are impacted
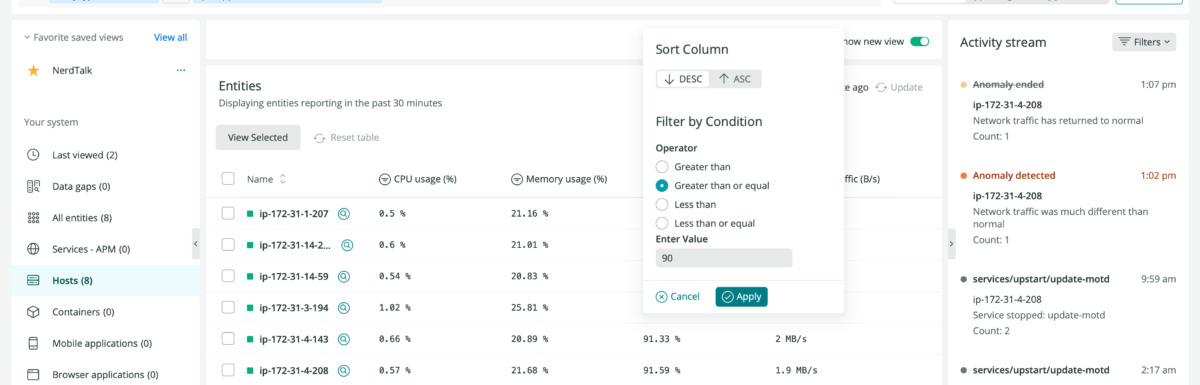
The New Relic platform finds potential issues before they affect your customers. Know exactly where to focus your attention with New Relic Lookout and gain faster incident resolution through automatically surfaced causes and effects. Dig deeper with correlations and abnormal history to see how it impacts your whole system—no configuration needed.
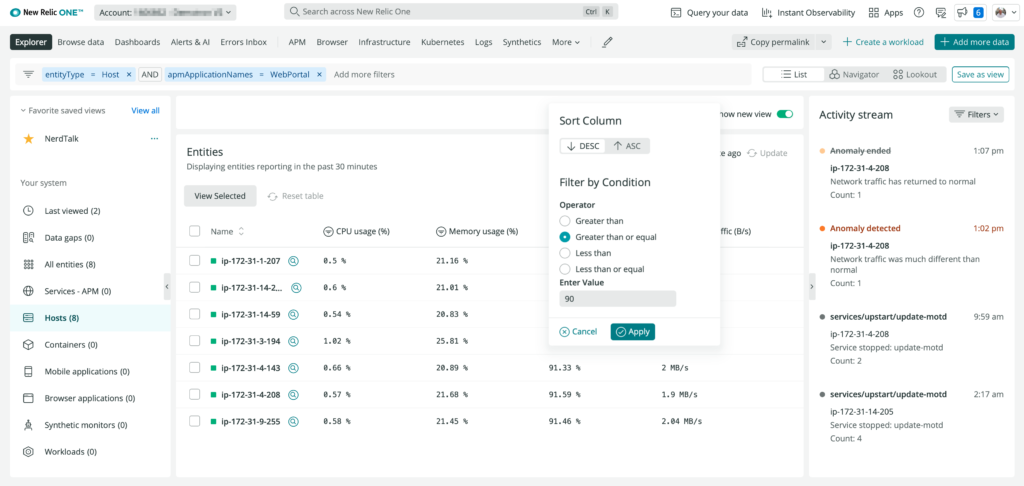
Pinpoint infrastructure monitoring bottlenecks
With this new interface in New Relic One, you can navigate tens of thousands of infrastructure entities to confirm and isolate possible bottlenecks by filtering and sorting based on golden signal conditions. Select multiple items to compare their golden metrics and understand how infrastructure items are related to applications and other connected architecture.
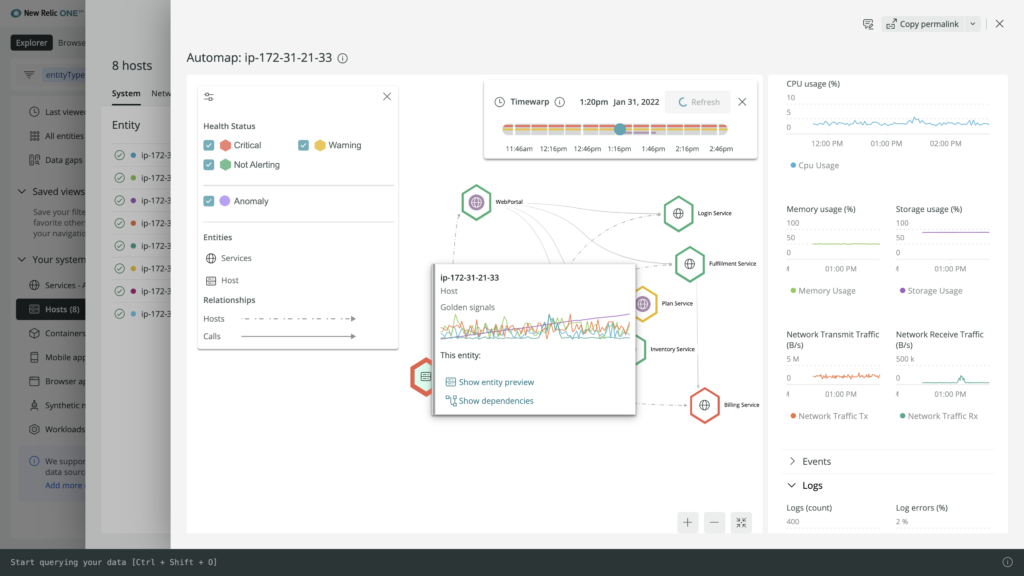
Quantify impact radius
Determine the impact of an incident by visualizing the upstream and downstream dependencies using automap. You can also analyze historical telemetry using timewarp to view health changes by going backward and forwards in time.
We use New Relic infrastructure monitoring to understand and optimize our infrastructure performance. New features of the enhanced interface are headed in the right direction. For example, with automap, we can see the impact radius of an issue, down to when it occurred and the applications impacted. I’m looking forward to it moving forward in the future.
Vadim Loginov
Senior SRE at The Rank Group
Investigate root cause of anomalies
Analyze related entities, logs, alerts, golden signals, network metrics, processes, and storage in context and in a unified experience to identify root cause and resolve issues faster.
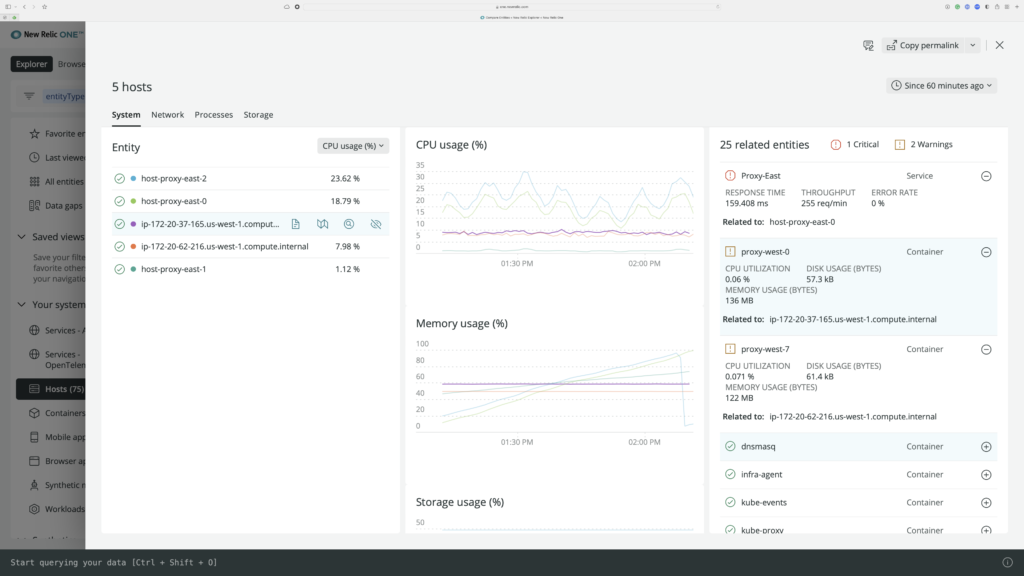
When we troubleshoot our infrastructure, we want to focus on specific components. New Relic gives us the ability to quickly filter our environment using tags, golden metrics, and so much more. We’re thrilled New Relic offers this level of functionality.
Bob Damato
Senior Director Software Engineering at Cox Automotive
Our customers rely on New Relic’s industry-leading Kubernetes cluster explorer as well as Pixie for instant, no-code observability, in addition to our breadth of on-host integrations and integrations to cloud vendors like Amazon Web Services, Microsoft Azure, and Google’s Cloud Platform which helps them achieve full-stack visibility.
With our new experience in New Relic One, we’ve doubled down on providing real-time troubleshooting workflows while incorporating broader platform context and unique topology visualizations into our user experience.
Next steps
Check out our new infrastructure monitoring experience and tell us what you think. New Relic full platform access users across all regions can start using it today without any additional cost.
- Find it in New Relic One within the main menu under Infrastructure > Hosts New.
- Read our infrastructure monitoring documentation.
If you’re not already using New Relic One, sign up for a free account, which includes 100 GB/month of free data and all New Relic One capabilities, including this new infrastructure monitoring experience.